在前一阵子参加了DevOps国际峰会(DevOps International Summit),《DevOps Handbook》和《Beyond The Phoenix Project》的联合作者 John Willis 在他的分享中提出了“Kubernetes将成为未来的主流”,再加上我所在公司有大量的微服务架构项目使用到了Kubernetes,遂开始学习Kubernetes。 那要去学习它就必须得有可操作环境,在Kubernetes官网 🔗提供了好多个解决方案。
我选择了难度稍高的 kubeadm 配合由 Vagrant 以及 Virtualbox 搭建的虚拟机创建 Kubernetes 的集群,通过使用 kubeadm 熟悉 Kubernetes 的部署流程以及它的原理。
目标
- 启动两个虚拟机,一个作为主节点,一个作为工作节点
- 熟悉 Kubeadm
- 在集群上部署Kubernetes-dashboard、nginx
开工
我使用MacOS作为运行环境写的这篇文章,在其它操作系统上进行操作可能会有一点不一样。另外,因为 Kubernetes 的镜像在谷歌的服务器,总所周知的原因,请先架好梯子,否则会出现下载不了镜像等“正常”现象。 梯子方面优先选择付费服务,可以减少你大量的工作。
编写 Vagrantfile
要在本地建立集群,那就先建两个虚拟机吧,这两个虚拟机配置、设定上应该是基本一致的,那就使用 Vagrant 做初始化,环境配置。使用 Vagrant 的一大好处是只需要一份Vagrantfile就可以保证使用它建立起来的虚拟机是一致的,并且自动地把下载镜像、初始化、配置等等全做好了。
既然是个集群,那它们之间应该可以相互通讯,需要配置一个私有网络;另外,Vagrant 默认创建的网络是 NAT 模式,那要有端口映射,预留端口 10000->80(master),10001->80(node);根据官网的介绍 🔗,所有节点推荐使用至少2核CPU,2G内存;同样根据官方文档 🔗,需要安装 kubelet,kubectl,kubeadm,docker。根据这些条件,就有了下面的Vagrantfile。
$script = <<-SCRIPT
echo "Update and install the kubeadm"
apt-get update && apt-get install -y apt-transport-https curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
apt-get update
apt-get install -y kubelet kubeadm kubectl docker.io
apt-mark hold kubelet kubeadm kubectl
usermod -aG docker vagrant
kubeadm config images pull
SCRIPT
Vagrant.configure("2") do |config|
config.vm.provider "virtualbox" do |v|
v.memory = 2048
v.cpus = 2
end
config.vm.define "master", primary: true do |master|
master.vm.hostname = "k8s-cluster-master"
master.vm.box = "ubuntu/xenial64"
master.vm.network "forwarded_port", guest: 80, host: 10000, protocol: "tcp"
master.vm.network "private_network", type: "dhcp"
master.vm.provision "shell", inline: $script
end
config.vm.define "node" do |node|
node.vm.hostname = "k8s-cluster-node"
node.vm.box = "ubuntu/xenial64"
node.vm.network "forwarded_port", guest: 80, host: 10001, protocol: "tcp"
node.vm.network "private_network", type: "dhcp"
node.vm.provision "shell", inline: $script
end
end启动节点
执行命令vagrant up,Vagrant 开始自动下载Ubuntu镜像,并执行我们写在Vagrantfile里的 Shell 脚本,顺利启动后,在当前窗口执行vagrant ssh master,新开一个窗口执行vagrant ssh node分别 ssh 进入到主节点以及工作节点。 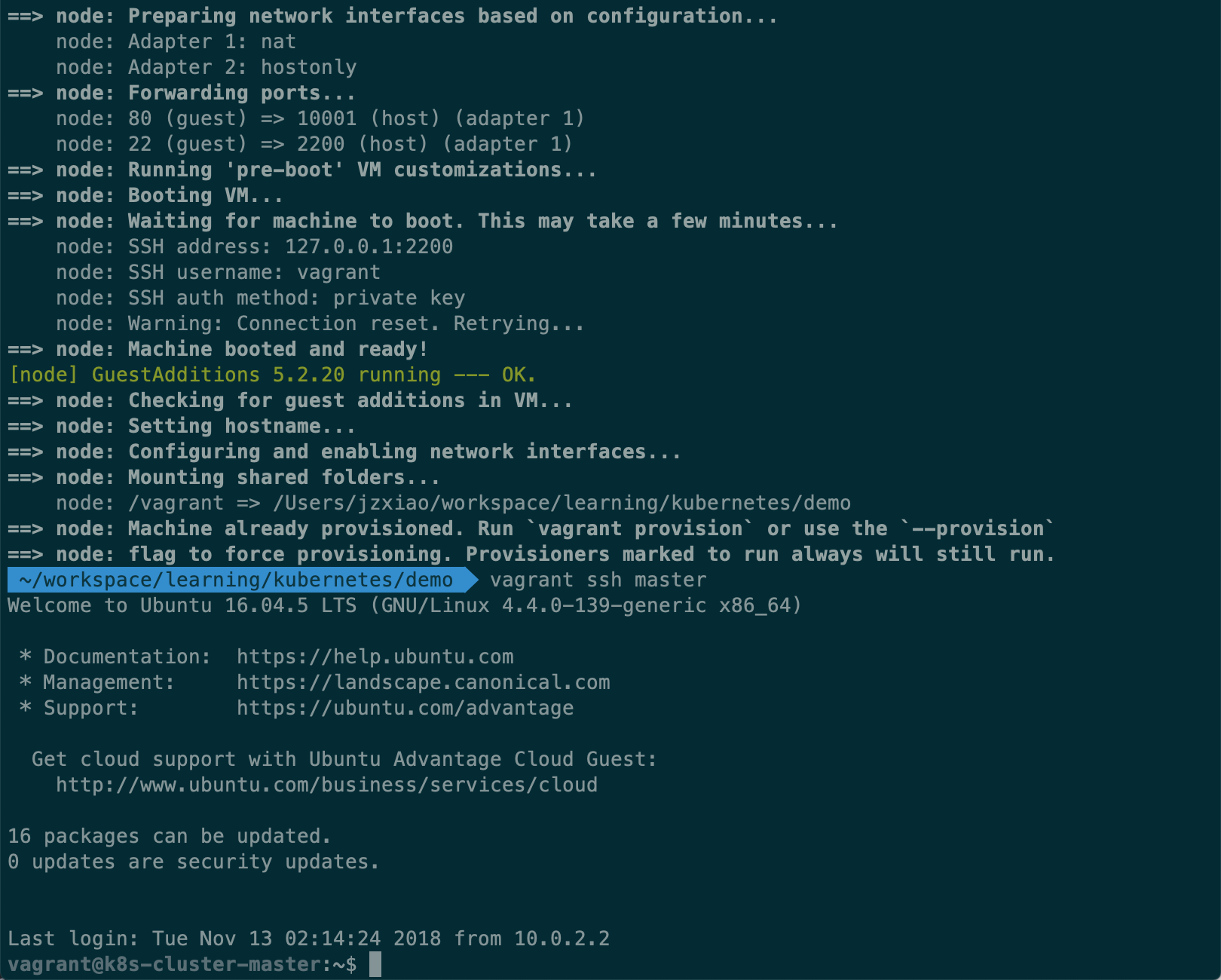 第一次执行
第一次执行vagrant up会看到更多的信息。
使用命令ip a查看当前节点 ip,两个节点互相 ping,检查连通性。
部署
过程没有想象中顺利,我完全跟着官网文档操作,却陷进到一连串的坑里,耗费了接近两周的时间才把 Kubernets 集群搭建起来。
Round 1 - Kubernetes 集群
我们一步一步按照官方文档 🔗,在主节点 k8s-cluster-master 执行sudo kubeadm init初始化节点,成功后,根据 kubeadm 的输出,执行接下来的命令。
- 复制 kubeadm 生成的配置文件,更改配置文件夹的权限
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config - 选择一个CNI 插件 🔗组建网络,我们这里选择了Weave Net
kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')" - 工作节点执行最后一句
sudo kubeadm join,加入到 Kubernetes 集群kubeadm join 10.0.2.15:6443 --token <token> --discovery-token-ca-cert-hash sha256:<hash> - 查看节点状态,Pods 状态
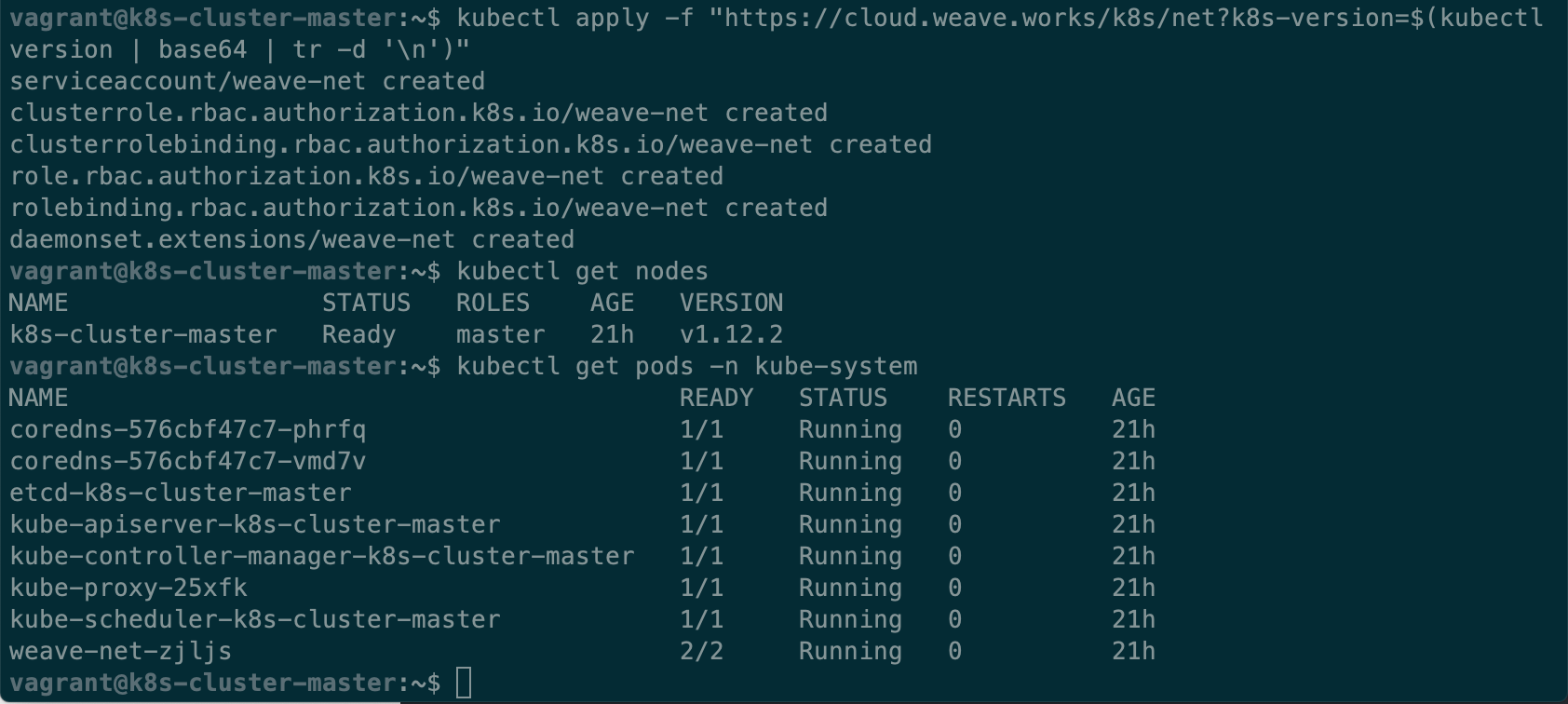
Round 1.1 - 工作节点无法连接到主节点
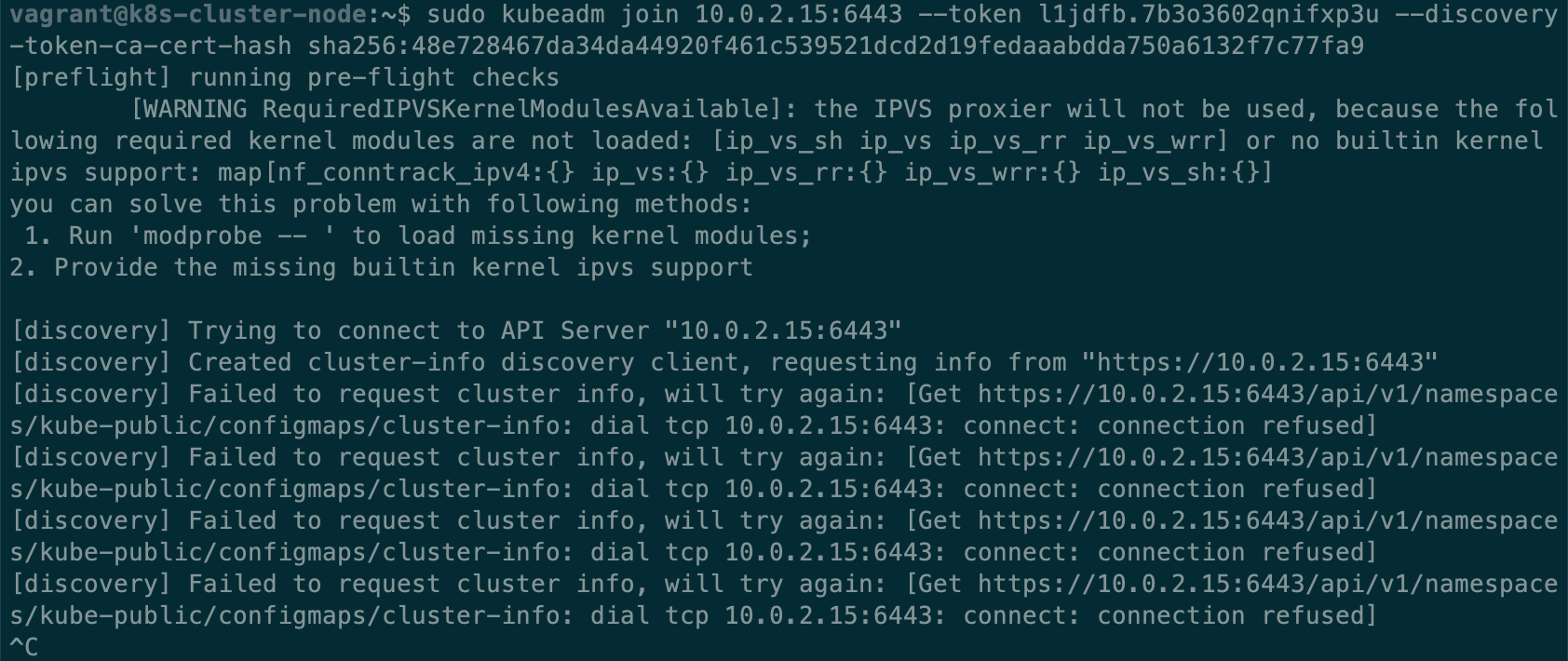
这里遇到第一个坑,工作节点无法连接到主节点的 Kubernetes api。在工作节点的 kubeadm join log,我们可以看到 kubelet 在不断地尝试访问 10.0.2.15:6443,曾经看过 VirtualBox 的说明文档,默认情况下 ip 10.0.2.15 是在虚拟机在宿主机网络里的 ip,所有的虚拟机都遵循这一设定,而工作节点需要访问的是主节点的 6443 端口,现在却在尝试 10.0.2.15,相当于不断尝试连接节点自身的6443端口,这明显不对。
因此,我们需要 kubelet 访问/提供正确的节点ip,查阅文档,发现 kubeadm 有一个参数 --apiserver-advertise-address=<ip>,显式指定 kubelet api server 的 ip 地址。
好吧,执行sudo kubeadm reset,加上参数,重新做一遍。
Round 1.2 - 工作节点 Not Ready
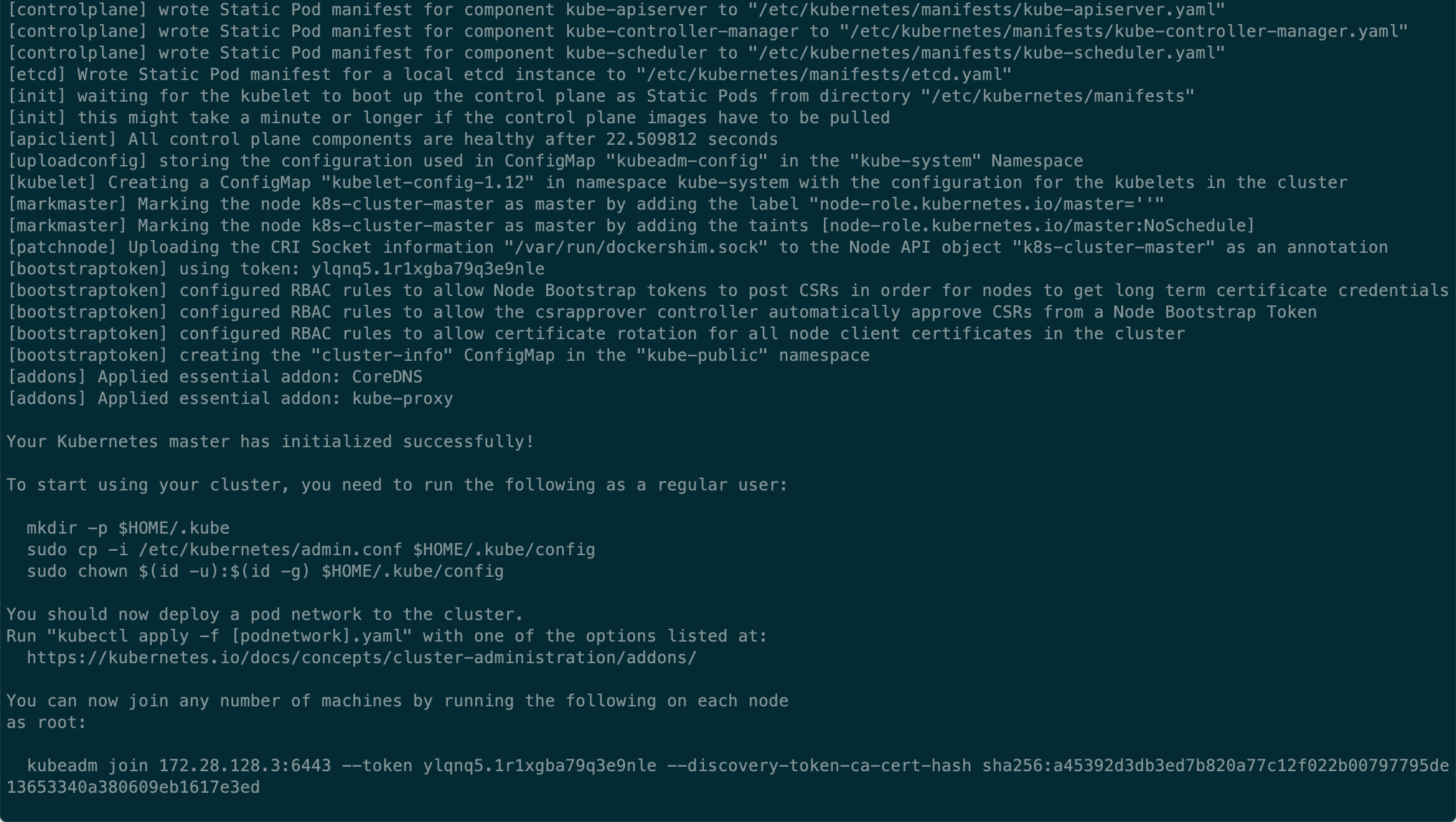
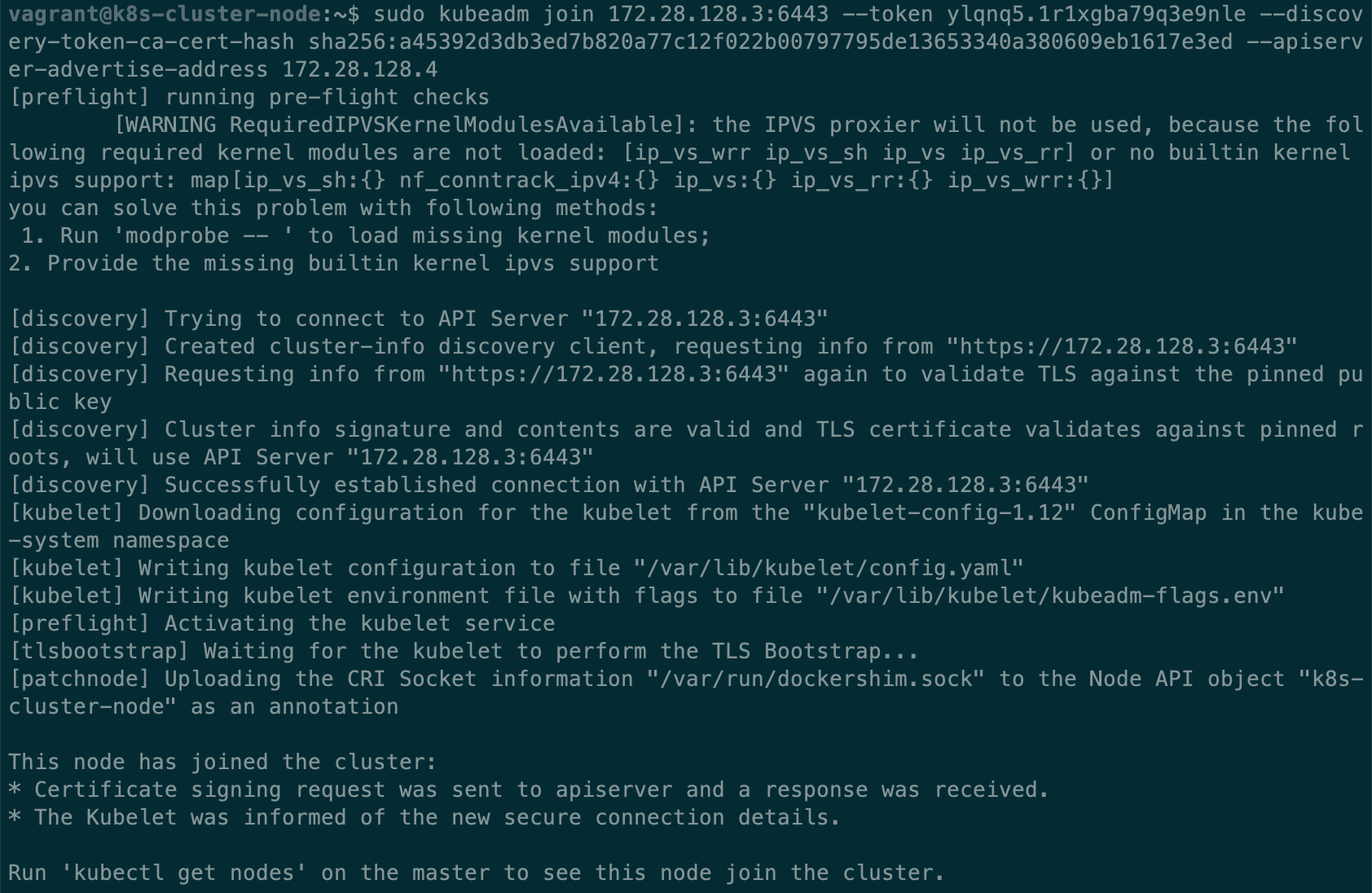
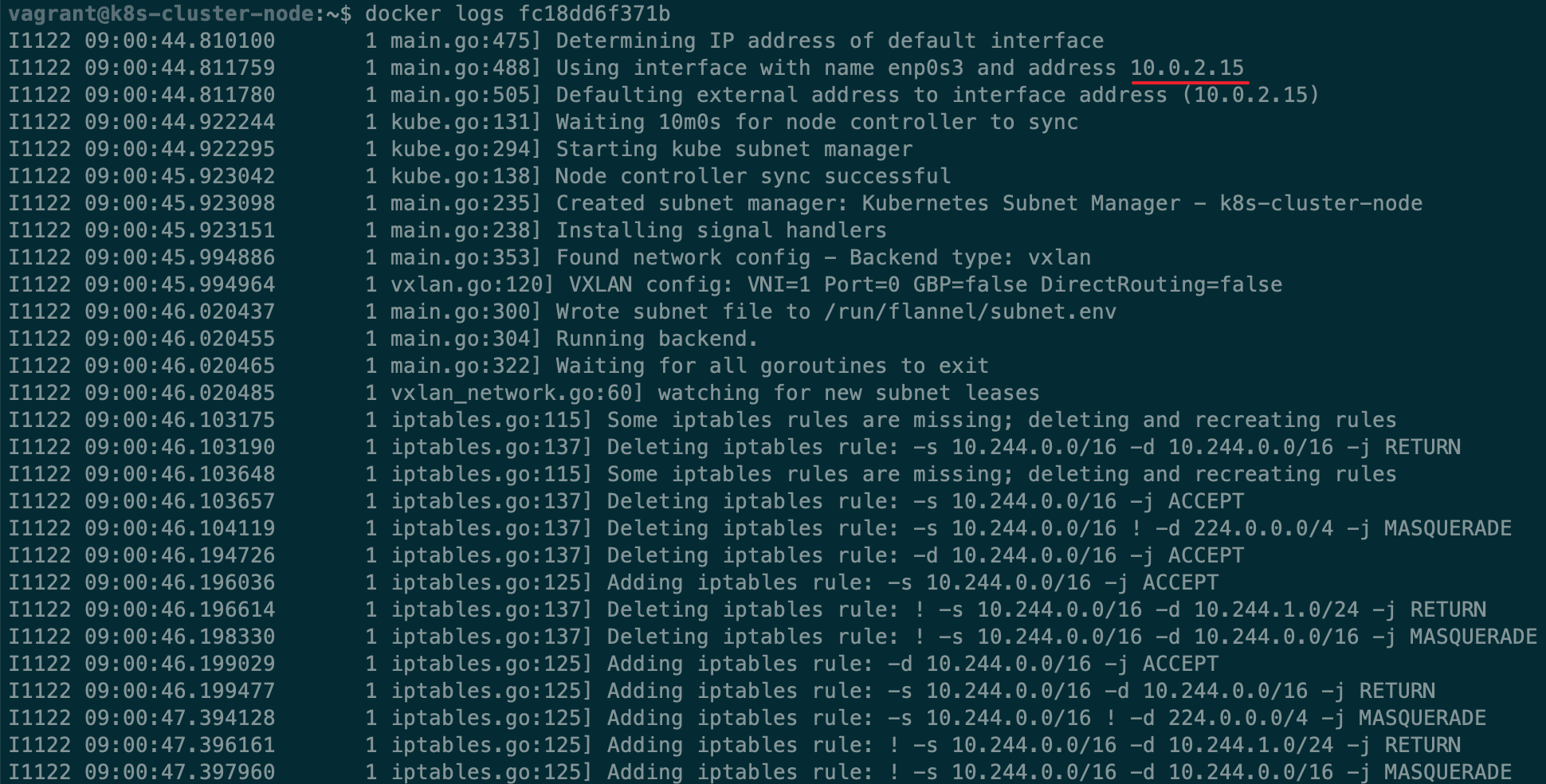
执行成功,但是当我们在主节点执行kubectl get nodes, kubectl get pods -n kube-system,可以看到 node: NotReady,weave 的 Pods 一直处于 CrashLoopBackOff 状态(这表示 Pod 创建失败,kubelet 在不断地重试),在工作节点查看 docker logs 发现 weave 一直在尝试连接 10.96.0.1:443,但是根据 docker logs 显示,以及通过 ping,telnet 检测,全 timeout,目标不可达。
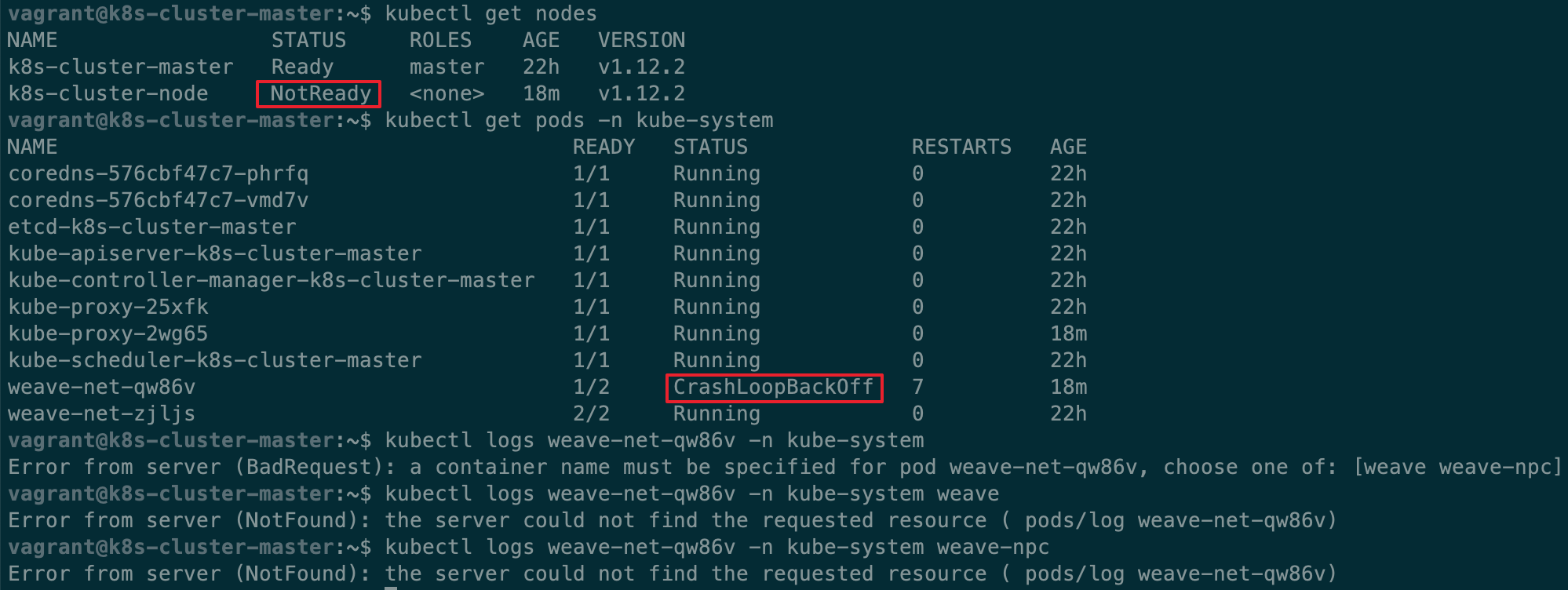
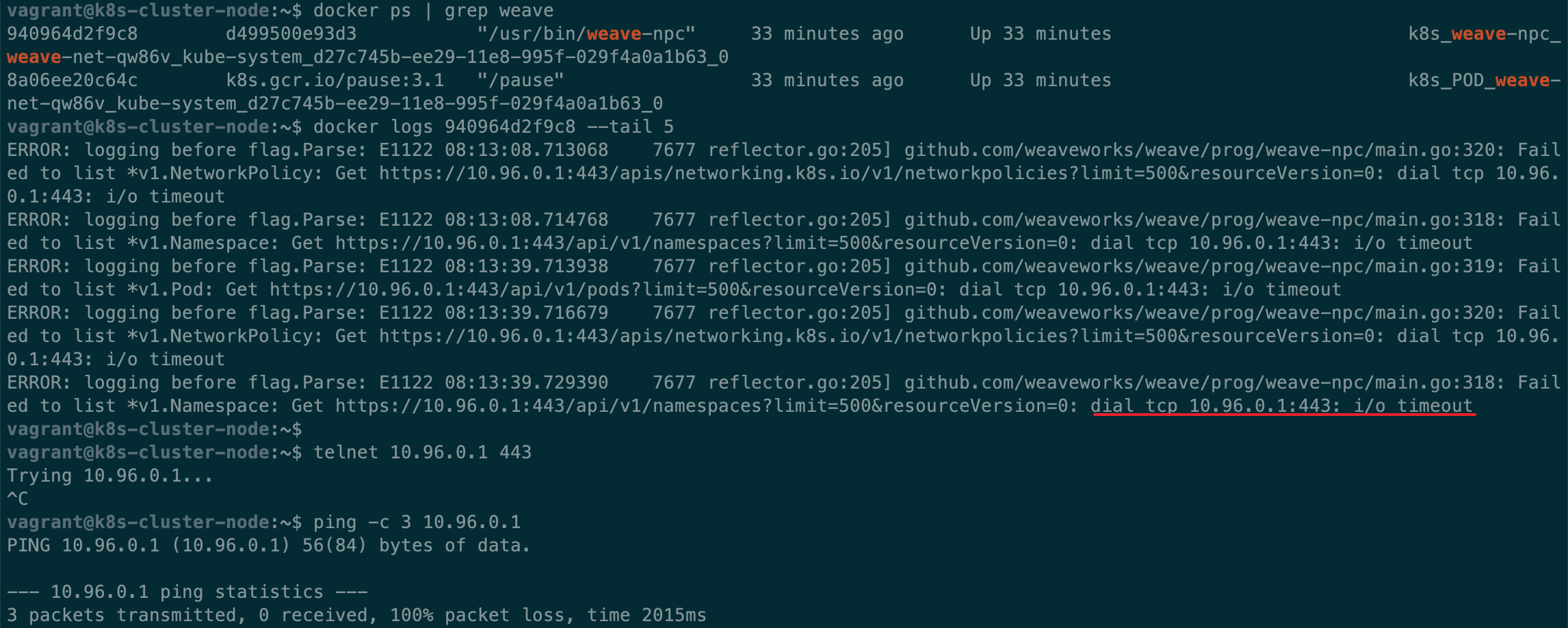
这个 ip 地址理应是 Kubernetes 提供的,经过一番查找,在 Services 里找到了这个 ip,kubectl get svc,可以看到返回结果表明 10.96.0.1 是 Kubernetes 本身在集群里的 ip。
不科学啊,节点之间是通的,难道是 CNI 插件有问题?换一个试试,在官网的教程里有好几个其它插件供选择,这次我选择了 flannel,跟 Weave Net 不太一样的是,它需要在 init 的时候加上一个额外的参数--pod-network-cidr=10.244.0.0/16,net.bridge.bridge-nf-call-iptables 必须设为 1,reset 集群,重新执行命令部署。
sysctl net.bridge.bridge-nf-call-iptables=1
sudo kubeadm init --apiserver-advertise-address 172.28.128.3 --pod-network-cidr=10.244.0.0/16
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/bc79dd1505b0c8681ece4de4c0d86c5cd2643275/Documentation/kube-flannel.ymlsudo kubeadm join 172.28.128.3:6443 --token 4puk29.w2ur96jtfuu9z22v --discovery-token-ca-cert-hash sha256:3973ee67977702c144f6f57613f8ce7765eac975990520846a15465fac625043 --apiserver-advertise-address 172.28.128.4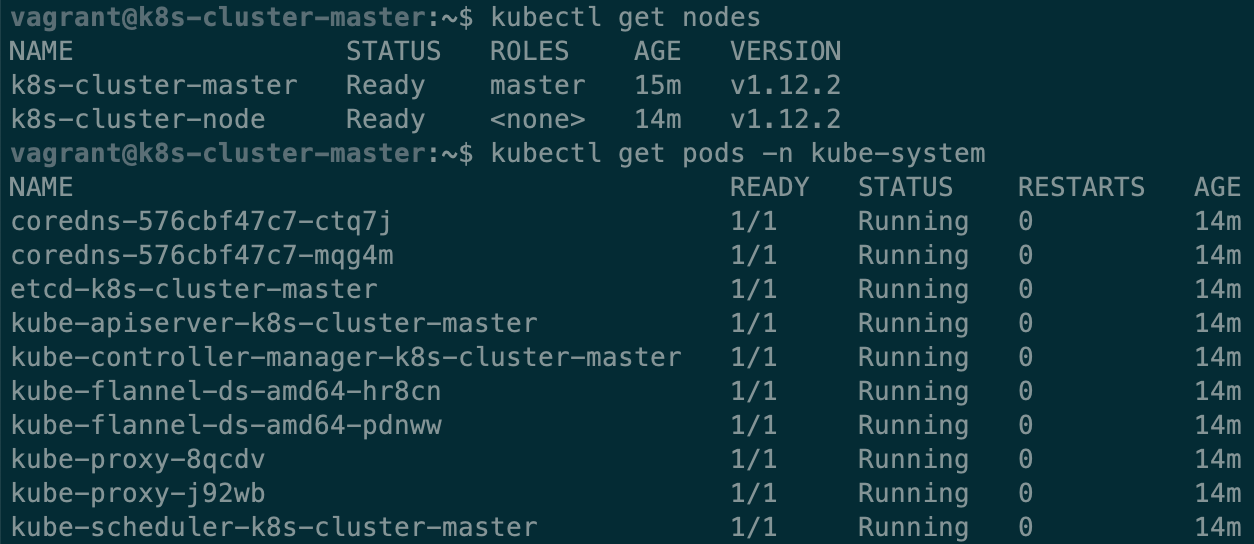
kubectl get nodes显示节点 ready,kubectl get pods -n kube-system显示所有 Pods 运行正常,great!
Round 2 - Kubernetes Dashboard
从Kubernetes Dashboard Repo 🔗获取部署命令,启动 Kubenetes Proxy,通过它访问 Dashboard: http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/ 🔗 。注意这里使用的是虚拟机的 localhost,所以我们更改 VirtualBox 的网络配置,添加一个端口映射到主节点的 8001 端口。(Kubernetes Proxy 就是一个反向代理,把外部请求通过主节点/集群,转发到工作节点/集群,避免直接暴露服务,降低安全风险)
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard.yaml
kubectl proxy --address 0.0.0.0 # 允许虚拟机之外的流量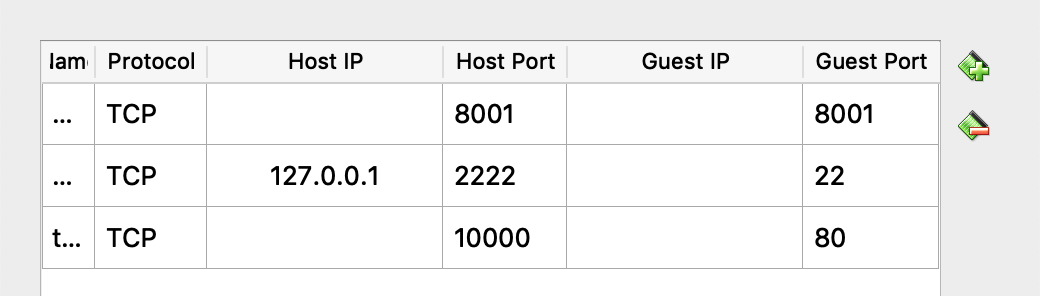
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "no endpoints available for service \"https:kubernetes-dashboard:\"",
"reason": "ServiceUnavailable",
"code": 503
}Round 2.1 - 503
执行命令kubectl get pods -n kube-system,发现 dashboard 跟之前 Weave Net 一样,无法正常创建 container,在工作节点执行docker logs <contianer_name|container_id>查看CNI插件的日志,发现它还是使用了 NAT 网卡的 ip 10.0.2.15,也就是虚拟机在自己的隔离网络的 ip,无法成功组网,在之前 “get nodes” “get pods” 显示一切正常,只是 flannel 跟 Weave Net 实现方式不一样而已。
大致原因清楚了,那怎么解决呢?“get nodes” 会不会有相关信息呢?接着,我找到了一个参数看到了各个节点的 ip,kubectl get nodes -o wide,可以看到所有的节点的 internal ip 都是 10.0.2.15。在刚开始,我不确定这个 “internal ip” 在 Kubernetes 里有什么含义,瞎找了一段时间,甚至修改 dashboard 的 yaml 文件,让它强制运行在主节点,但在后面部署其它 APP 的时候都出现了错误,无法被正常访问,只好继续寻找其它解决办法,最终让我在官方文档找到了更改它的方法。
这个 internal ip 定义在 kubelet 的启动参数,默认使用的是系统第一个网卡的 ip,在 kubelet 的启动参数里,它叫 “node-ip”。有两种方法,
- 通过 kubeadm 控制 kubelet 启动参数
- 直接更改 kubelet 的启动参数
首先尝试使用第一种方法,然后发现 kubeadm 不可以通过命令参数更改 kubelet 的启动参数,只能通过提供一个包含启动参数的配置文件给 kubeadm。关于这一部分的信息,在网上只有较少可以参考,通过搜索引擎找到了 GitHub 上有 issue 提到了通过创建一个配置文件达到我们的目的,而且我们可以把所有 kubeadm init, kubeadm join 的其它所有参数都定义在 kubeadm 的配置文件里,而 node ip 的更改也比较简单,只需要通过参数 “kubeletExtraArgs” 设置额外的参数个 kubelet 就可以了。
但有一部分参数,例如关于 “apiserver-advertise-address” 的设定始终不生效,最后凭借 GitHub 上的关键字在 kubeadm 的文档里找到了相关描述,原来它使用的配置文件的方法还是处于 alpha 阶段,而且 kubeadm join 需要用到的 token 是生成的,没办法写死在配置文件,再三考虑,还是放弃了这种办法,还是使用原来的办法,再配合一个脚本,更改 node ip,脚本内容如下,执行完后,重启 kubelet,docker ,使配置生效。
---
apiVersion: kubeadm.k8s.io/v1alpha3
kind: InitConfiguration
apiEndpoint:
advertiseAddress: 172.28.128.3
nodeRegistration:
kubeletExtraArgs:
node-ip: 172.28.128.3
pod-network-cidr: 10.244.0.0/1#/bin/sh
COND_NODE_IP=`sudo grep "node-ip" /var/lib/kubelet/kubeadm-flags.env | wc -l`
if [[ ${COND_NODE_IP} = 1 ]]; then
echo "--node-ip had been set, skipped"
exit 0
fi
sudo sed -i '/^.*/ s/$/ --node-ip=172.28.128.3/' /var/lib/kubelet/kubeadm-flags.env
sudo systemctl restart kubelet#/bin/sh
COND_NODE_IP=`sudo grep "node-ip" /var/lib/kubelet/kubeadm-flags.env | wc -l`
if [[ ${COND_NODE_IP} = 1 ]]; then
echo "--node-ip had been set, skipped"
exit 0
fi
sudo sed -i '/^.*/ s/$/ --node-ip=172.28.128.4/' /var/lib/kubelet/kubeadm-flags.env
sudo systemctl restart kubelet docker
尝试部署 dashboard,还是不能访问,期间还尝试了好几种办法,包括:修改 flannel 的 YAML 文件;reset,重建虚拟机;切换其它的 CNI 插件;等等。无头绪之际,在 flannel 的 Github Wik 🔗 看到了一个很关键的信息:
Vagrant typically assigns two interfaces to all VMs. The first, for which all hosts are assigned the IP address 10.0.2.15, is for external traffic that gets NATed.
This may lead to problems with flannel. By default, flannel selects the first interface on a host. This leads to all hosts thinking they have the same public IP address. To prevent this issue, pass the
--iface eth1flag to flannel so that the second interface is chosen.
默认使用网卡0?! IP address 10.0.2.15 ?!这应该就是一直出问题的根源了!为了简单,我们还是切换回 Weave Net,kubeadm reset,把所有的东西重置,继续试验。
重置完成后,重新按照之前的流程,初始化,安装 CNI 插件(Weave Net)。Weave Net 还是在不断尝试连接 10.96.0.1。结合刚才看到的 flannel 的说明,跟踪路由看看请求去了哪里,在工作节点执行命令traceroute 10.96.0.1,可以在结果看到请求被路由到宿主机的网络了… 难怪一直无法连接,它在尝试连接到我们宿主机的内网 ip 为 10.96.0.1 的机器。
看下面👇截图里还有一个 ip,路由第一跳是 ip 10.0.2.2
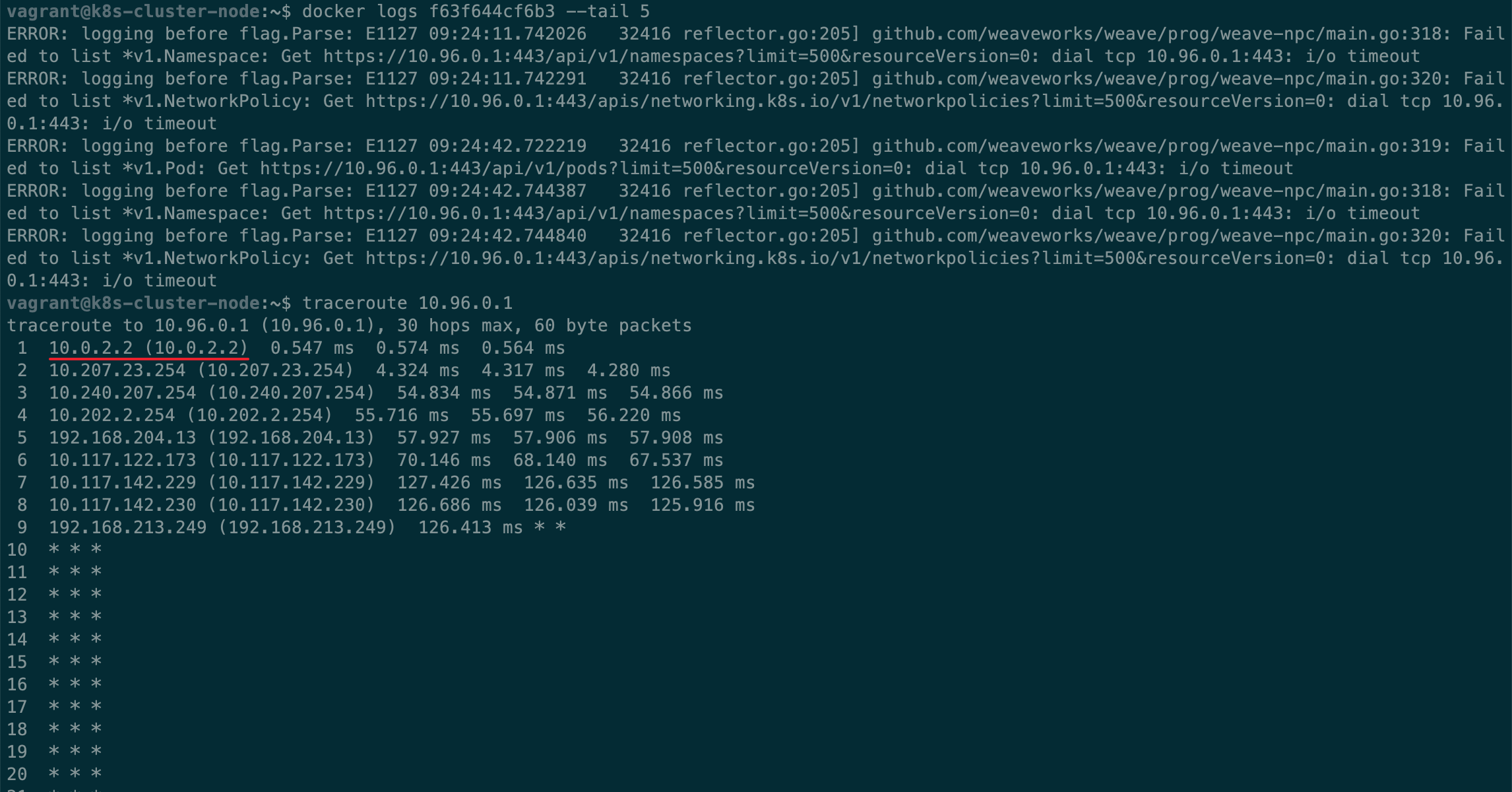
灵光一动,想起来以前碰到过因为路由设置错误导致的网络问题,特意去复习了一下 Linux 路由知识。
在各个节点执行命令ip route查看路由表,可以看到虚拟机的路由表设置是让默认的请求全都通过 10.0.2.2 也就是宿主机的 NAT 网卡作出网络请求,
工作节点需要正常的连接到主节点,那么就必须让它的流量走 Host Only 网络,也就是网卡1,而不是通过网卡0上的 10.0.2.2 去尝试连接到宿主机的网络主机。
检查虚拟机 Host Only 的网卡的设置,在宿主机 Terminal 执行ifconfig查看对应的网卡的 ip 地址,这个 ip 就是我们用于让两台虚拟机正常通讯的路由 ip。
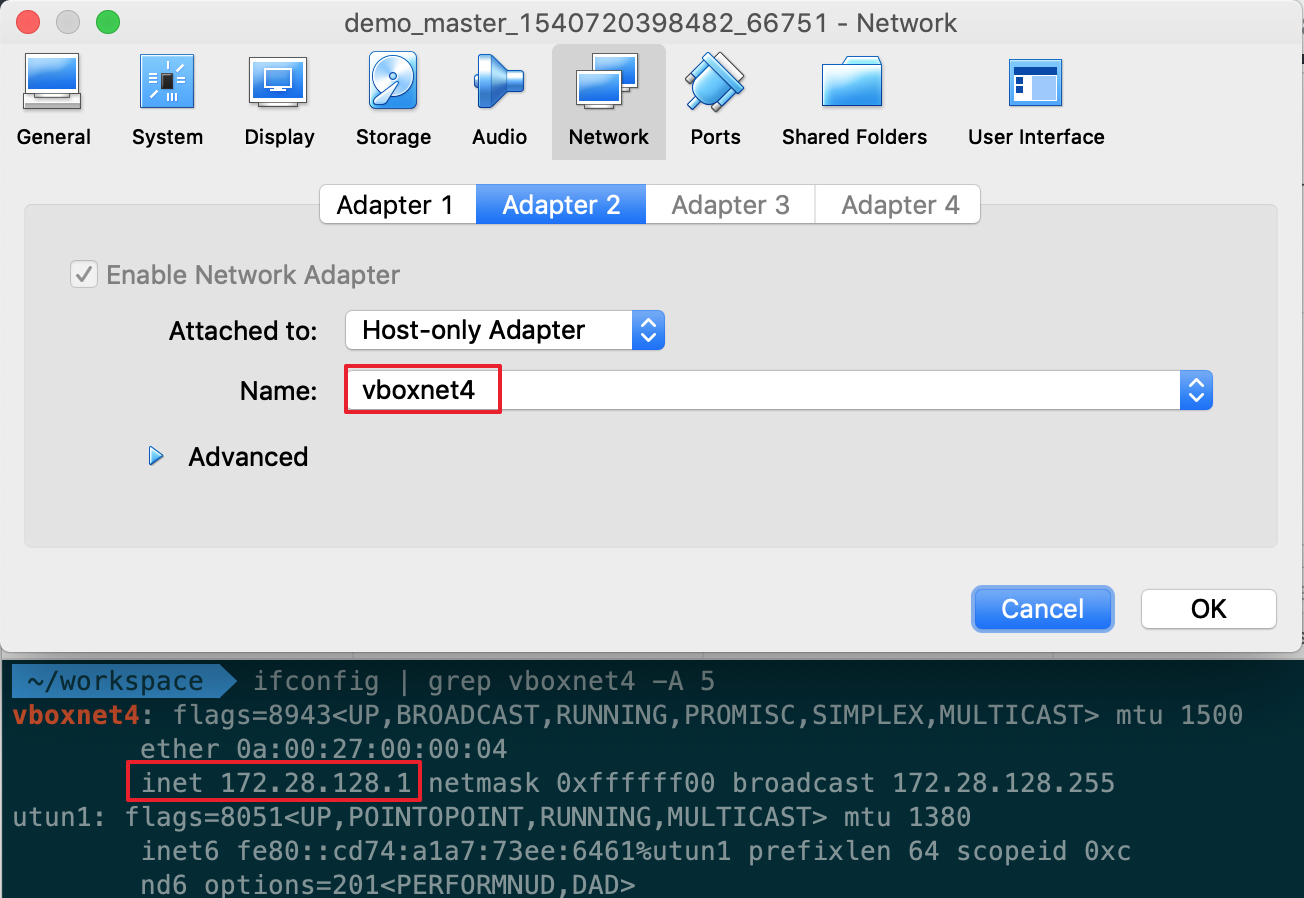
使用 kubeadm reset 重设所有设定,别忘了执行之前写的更改 node-ip 的脚本,执行 ip route 相关的子命令更新路由表,让工作节点所有的流量通过网卡1,进而正确地让主节点、工作节点互相通讯。执行顺序如下。
# 在各个节点执行
ip route #查看路由表
sudo kubeadm reset
# master节点
sudo kubeadm init --apiserver-advertise-address=172.28.128.3
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
bash change-kubelet-node-ip.sh
# node节点
sudo kubeadm join 172.28.128.3:6443 --token <token> --discovery-token-ca-cert-hash <token> --apiserver-advertise-address=172.28.128.4
bash change-kubelet-node-ip.sh
sudo ip route del default via 10.0.2.2 && sudo ip route add default via 172.28.128.1执行以下命令部署 Kubernetes Dashboard,在宿主机访问 http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/#!/login 🔗 验证部署结果。
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
kubectl proxy --address 0.0.0.0Nginx
创建 NGINX 的yaml。
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
svc: nginx
type: ClusterIP
ports:
- port: 9999
targetPort: 80
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 2
revisionHistoryLimit: 3
selector:
matchLabels:
svc: nginx
template:
metadata:
name: nginx
labels:
svc: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
protocol: TCP- 执行命令
kubectl apply -f nginx-rs.yaml部署 nginx - 启动 Kubernetes proxy
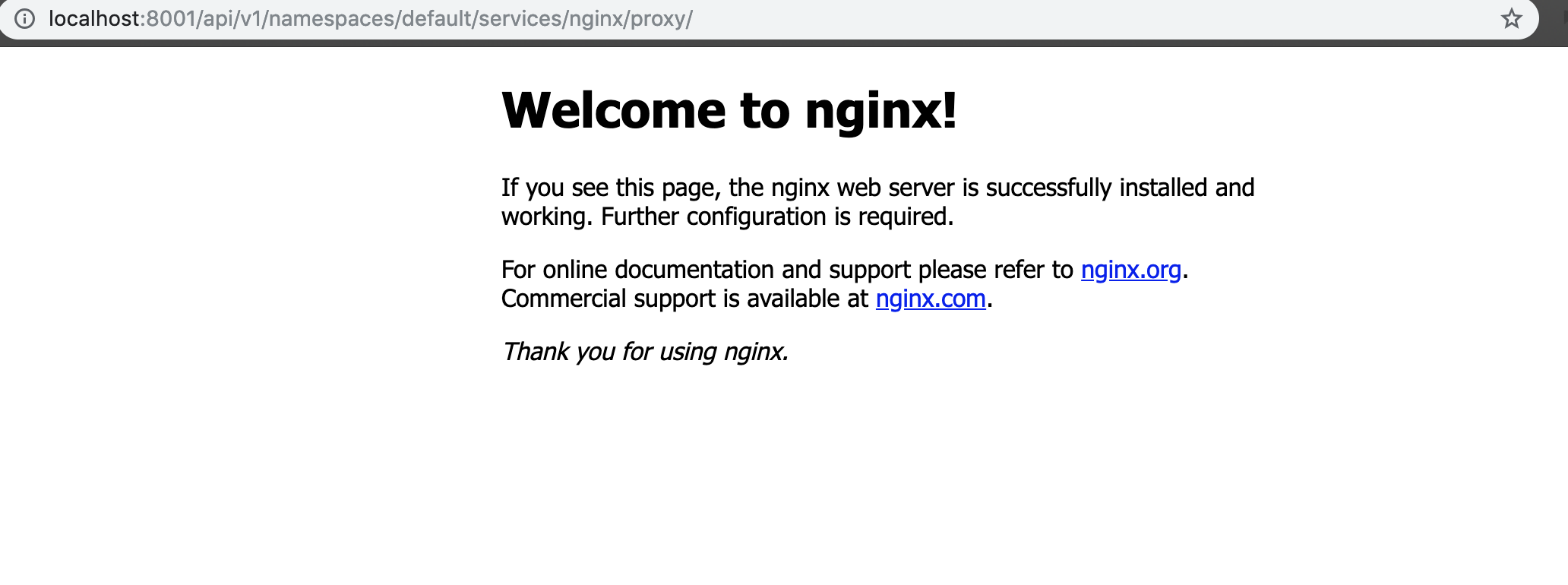
kubectl proxy --address 0.0.0.0 - 根据官方文档相关描述 🔗,在宿主机访问如下链接 http://localhost:8001/api/v1/namespaces/default/services/nginx/proxy/ 🔗
- 如果一切顺利,你将看到如下页面
待续
当初想写这篇文章是为了记录 Kubernetes 在本地虚拟环境下的集群部署流程的,没想到因为工作变动、踩坑、怠惰,使得这一篇文章拖了这么长的时间,因为对原理不熟,期间重复了很多次操作,以至于整个流程记录下来非常冗长,而且期间中断了好几次,所以语句可能会有不连贯的情况。接下来我将会重整整个流程写一篇姊妹篇 TL;DR 版,敬请期待。